Product manager, Luc Berrewaerts, engineers, Romain Dupuis and Matthew Philippe helping companies enhance their data management through automation and scalability.
Impeding Problems
After years of organic systems evolution, legacy infrastructure and paralysed processes, making sense out of siloed data can be somewhat of a daunting task.
A leading investment bank approached us recently to review their data management to support new analytics use cases. The existing systems could not process a growing volume of data while serving more applications in a reasonable amount of time. In addition, their ownership costs skyrocketed and their increasing dependency on external developers started to be a serious concern.
The bank needed to find a new system that would resolve those issues, so they could fully unlock the value of their current data. If such a system exists, that would mean migrating the existing data pipelines, more than a thousand. Those data pipelines were initially built from another tool. Hopefully, they could be dumped under the form of SQL files. Still, migrating such a great number of SQL files manually can be quite a challenge.
They wanted to see if we could help them automate the migration of the existing data pipelines while allowing them to build new data pipelines to feed any new type of application consuming data without affecting the performance or increasing the ownership cost.
They also wanted to understand how they could better govern their data in an environment that offers a one-stop shop from usage of sources, combination of queries to API extraction.
Project Description
Let’s set the scene here.
The bank provided us with a set of more than a thousand SQL files, describing the data sources, transformations and target tables of their BI data pipelines. They also provided around 600 CSV files containing 3 days of data to be used as input: there were 200 source tables and for each table, we received 3 files, 1 per day.
Digazu can collect the source data, apply transformations, and distribute the results to a BI tool. Yet, the real challenge was to reverse-engineer the provided SQL files while translating them into Digazu dataflows yet, considering the unstructured format of the files, the difficulty of the task escalated.
As an example, one target table could depend on several inputs. Each of these inputs were in fact intermediate results, built from other inputs, which could also be intermediate results built from yet other inputs. These dependencies were not documented, and could only be found by exploring and analysing the 1000+ provided SQL files.
So, one of our objectives was to rationalise all these transformations using the Digazu components.
The Digazu Approach
In Digazu, one dataflow defines the end-to-end flow of data collected from the sources to one target (= one table in this case). It can be visualised as a graph, starting from the sources, going through several transformations, to finally end-up in a target.
With this in mind, our approach was to replace the imbricated SQL files by dataflows, clarifying at the same occasion the complete data lineage and setting the foundations for better governance.
The process was broken down into two major steps: i) parsing the SQL file into configuration files usable by Digazu and ii) registering all the sources, transformations, and targets into Digazu.
Parsing
Parsing the SQL files required building reverse-engineering tools able to extract the needed information in order to build the Digazu configuration files.
This tool built a directed acyclic graph starting from the target and going upstream through the SQL files by extracting metadata for each SQL transformation (what were the sources, what were the transformations to apply, where should the result be distributed). This extraction was performed mainly with regular expressions and existing SQL parsers. Then, based on the extracted metadata, the configuration files were created.
The following figure depicts the different steps of the parsing process.
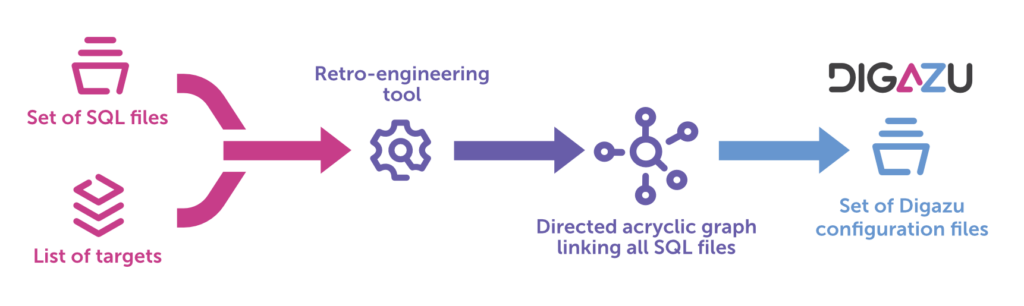
The parsing process was fundamental to the success of the migration. It helped better understand the structure of the SQL files by making all the dependencies explicit.
Here is a representative example of the SQL files we had to migrate:
CREATE VIEW schema.target AS
SELECT *
FROM transfo3 WITH “transfo3” AS
(
SELECT *
FROM ((source.b
INNER JOIN source.c
ON source.b.column1 = source.b.column1)
INNER JOIN transfo2
ON source.b.customer = transfo2.customer WITH “transfo2” AS
(
SELECT *
FROM source.c
INNER JOIN transfo1
ON source.c.country = transfo1.country) WITH “transfo1” AS
(
SELECT *
FROM source.a)The following shows how our parsing tool was used. It required two parameters: the set of SQL files, which we used to capture all dependencies between the user’s transformations, and the name of the table or view which we wanted to translate in Digazu.
$ pip install digazu
$ digazu sql_parser –sql_files_path sql_files/*.sql –target_name “schema.target” > payload.json
> [digazu sql_parser] Parsing 1 file(s) …
> [digazu sql parser] Found 6 nodes (3 sources, 3 transforms)!
> [digazu sql parser] Extracting dag for “schema.target”…
> [digazu sql parser] DAG extracted! It has 6 nodes (3 sources, 3 transforms)
> [digazu sql parser] Converting to digazu API payload …
> [digazu sql parser] Done!
$As a result, we got a `.json` file which we used as a payload for the Digazu API.
Registration With API
After the creation of the dataflow configuration files using our parsing tool, the stage was set for Digazu to do its job thanks to the API:
- Register the data sources and ingest data: As source registration in Digazu is configuration based, we were able to automate it by scripting. First, the script generated the configuration files based on the description of the data sources. Then, it submitted them to the Digazu API. In a matter of minutes, all sources were connected to Digazu, and real-time data ingestion was activated.
- Create the dataflows to transform and distribute data: As for source registration, the creation of dataflows is configuration based. By using the parsing tool described above, the needed configuration files were generated, then submitted to the Digazu API.
Real-time dataflows were then running in Digazu, transforming and distributing data in real time. The whole task took a few minutes.
The Digazu API allowed users to interact with the platform programmatically by declaring the resources with configuration. The users were able to tackle projects at scales unreachable for a human operator. In this particular case, the API was used to develop a domain-specific abstraction for that particular use-case.
We wanted to interact with Digazu using a terminology that would be immediately understood by the user. For instance, the parsing tool was just `digazu sql_parser`. Creating a dataflow (and all dependent resources) given the configuration file provided by the parsing tool required the following one-line command:
> digazu apply payload.json
Under the hood, Python scripts would make a succession of calls to deploy dataflows

The above figure shows the output from the dataflow deployment. The configuration files were successfully converted into real-time data pipelines in Digazu. The tool managed to identify the complete set of transformations, sources and the unique target. In this case, SQL transformations 1 and 2 served as intermediate results for the transformation 3 building the final target.
In fact, the same data sources could be re-used in a secured and governed way for multiple use cases and applications. Here, as many sources were already ingested for the BI use case, it only took a few clicks to re-use them for other use cases. Not to forget that all use cases benefited from real-time views and were continuously updated.
We demonstrated how scalable the bank could be using Digazu. Indeed, Digazu ensured an end-to-end integration of all the needed data processing from ingestion, transformation to distribution. The API Extraction is configuration based and the declaration or the definition of sources and data flows is programmable.
All of which compose great enablers for automation, making the process of scaling from one to many use cases relatively simple. In fact, all the data in Digazu might be combined to serve the needs of any downstream use-case, across BI and data science. That was another benefit of providing a unified approach to data.
End Results/ Benefits
As a result, hundreds of real-time end-to-end data pipelines are running in Digazu.
At the end of the process, we were able to construct an automated migration path for the existing data pipelines to automatically flow and centralise in Digazu. With such architecture in place, we were able to track lineage and provide end-to-end data visibility on dependencies, pipelining and data chain.
Not only that, but we have succeeded in showing them how this production-ready environment can serve all their downstream needs and scale for all their current and future data-driven use cases.