Businesses continually seek to maximise the value of their data assets, and data productisation stands out as a powerful strategy. But what exactly defines a data product, and how does it transform the way businesses use their data?
At its core, data productisation is the process of packaging any dataset into a valuable asset or «product» that can be easily understood, accessed, and utilised by different stakeholders within an organisation.
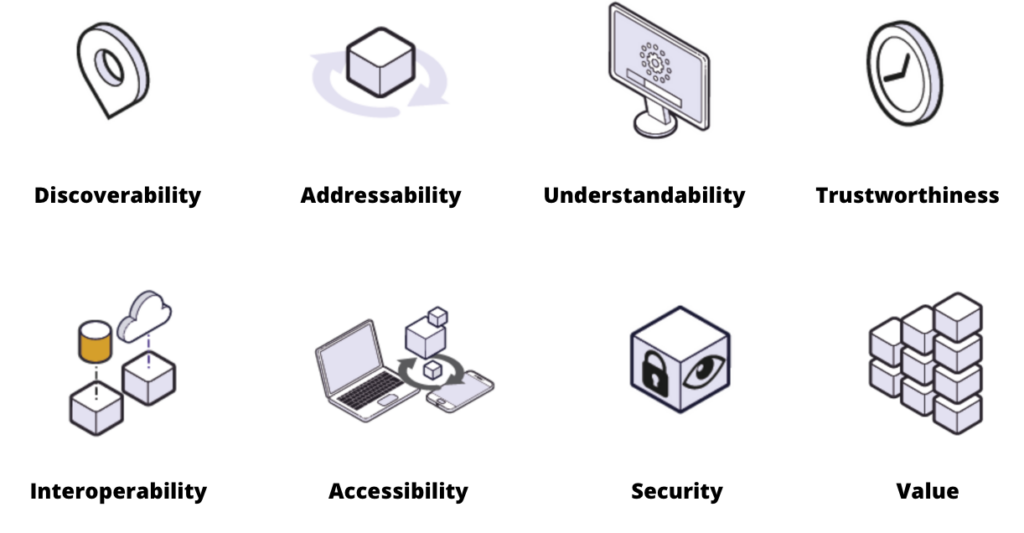
Our approach to data productisation is guided by several fundamental principles:
Discoverability – Data products should be easily located, with supportive information like domain, owner, lineage, and quality metrics readily available. This information serves to contextualise the data, enhance its reliability, and establish its relevance to users’ needs, thereby facilitating informed decision-making and maximising the value of data assets.
Addressability – Consistent access is essential for enhanced operations. Achieving addressability involves standardising naming, formats, and assigning unique permanent addresses to data products,
Standardising naming conventions ensures clarity and consistency, facilitating easy identification and access to relevant data products. This streamlines data retrieval, reducing confusion and duplication risks. Additionally, standardised formatting enhances interoperability and usability, enabling seamless integration with existing systems. Unique permanent addresses ensure persistent access and traceability throughout the data lifecycle, establishing a robust foundation for data governance and compliance.
Understandability – Comprehensive documentation and clear schema description enable easy interpretation of the data product. Indeed, data schemas with well described semantics and syntax will enable self-serve data products.
By understanding the structure and meaning embedded within the data schema, users can effectively navigate and extract insights from the data product. The self-service mode enhances efficiency and autonomy while establishing a culture of data-driven decision-making within the organisation.
Trustworthiness – Adherence to service-level objectives establishes trust. This includes aspects like change intervals, timeliness, completeness, freshness, availability, performance, and lineage.
Change intervals delineate the frequency and timing of updates or modifications to the data, ensuring that users have access to the most current information. Timeliness ensures data responsiveness for real-time decision-making. Completeness guarantees all necessary information for analysis. Freshness reflects data recency. Availability minimises downtime while performance ensures efficient responsiveness.
Lineage provides transparency into data origins and transformations, enabling users to trace its journey from source to consumption. By adhering to these service-level objectives, data products instil confidence and reliability, fostering trust among users and stakeholders.
Interoperability – Data products should easily blend with others. Standardised metadata and types foster enterprise-wide data harmonisation.
Standardised metadata provides a common language for describing data attributes, facilitating mutual understanding and compatibility across different systems and platforms. This ensures that data products can communicate effectively with one another, regardless of their origin or format.
Similarly, standardised data types establish consistency in how data is represented and interpreted across various applications and environments. By adhering to standardised data types, organisations promote interoperability and reduce the risk of data inconsistency and misinterpretation.
Accessibility – The usability of a data product is closely related to how easily it is for data users to access it with their native tools. This property refers to the possibility of accessing data in a manner that aligns with the domain teams’ skill sets and language. For example, data analysts will most likely use SQL to build reports and dashboards. Data scientists, in turn, expect data to come in a file-based structure to train artificial intelligence models.
Security – Security lies at the core of data productisation, necessitating robust measures to uphold access control, ownership, and governance standards.
Data products must prioritise access control, ensuring that only authorised individuals can access sensitive information. This involves implementing role-based access controls, encryption protocols, and multi-factor authentication to safeguard data from unauthorised access or misuse.
Clear ownership definitions and enforcement establish accountability, supported by policies and procedures for data stewardship. Governance standards maintain data integrity, reliability, and compliance, including data quality frameworks, data retention policies, and data lineage tracking mechanisms.
Value – The ultimate test of a data product is its utility – enhancing business performance. Usage and contribution to business results demonstrate its value.
By integrating these properties, data products transform raw and transformed data into actionable, valuable assets, offering immense potential for business impact.